

We have learned about HashMap in java and how does it work internally. As we have seen HashMap doesn’t support multithreading. To support multithreaded environment to HashMap, Java provides ConcurrentHashMap in java that is part of the Concurrency Collection Classes. The ConcurrentHashMap is used in a multi-threaded environment to avoid ConcurrentModificationException.
Here is the table content of the article will we will cover this topic.
1. ConcurrentHashMap in java?
2. Important points about ConcurrentHashMap in java?
3. How to create ConcurrentHashMap?
4. constructors of ConcurrentHashMap class?
5. ConcurrentHashMap internal working?
6. How does ConcurrentHashMap implementation increase performance?
7. Why we need ConcurrentHashMap in java?
8. Java ConcurrentHashMap example?
9. Fail-safe iterator in ConcurrentHashMap?
ConcurrentHashMap in java
The ConcurrentHashMap class extends AbstractMap class and implements the ConcurrentMap interface, Serializable interface also. It was introduced in JDK 1.5.


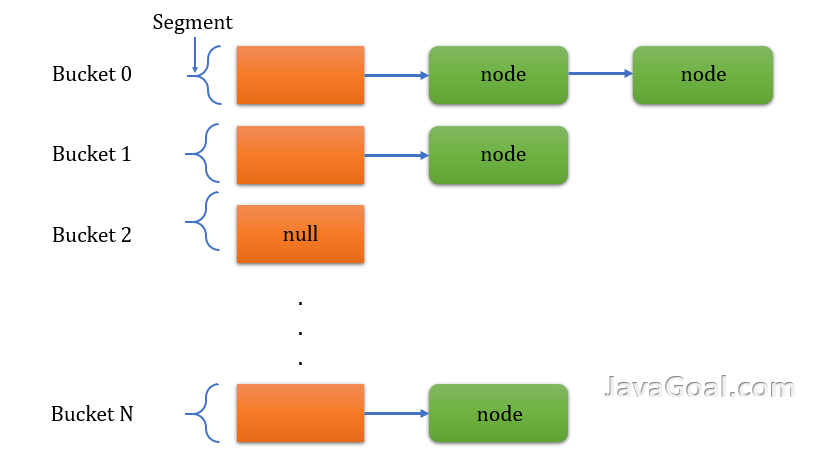
Like HashMap, ConcurrentHashMap provides similar functionality except that it has internally maintained concurrency. It is the concurrent version of the HashMap. It internally maintains a HashTable that is divided into segments. The number of segments depends upon the level of concurrency required the Concurrent HashMap. By default, it divides into 16 segments and each Segment behaves independently. It doesn’t lock the whole HashMap as done in HashTables/SynchronizedMaps, it only locks the particular segment of HashMap.
Important points about ConcurrentHashMap in java
1. The ConcurrentHashMap internally uses the HashTable as a data structure. Like Hashtable is threaded safe, but it provides all the functionality of HashMap except the thread-safe.
2. The ConcurrentHashMap internally divides the HashTable into segments. Each segment can work independently and access by a separate thread. It means different threads can perform operations on different segments.
3. In ConcurrentHashMap, the Object is divided into a number of segments according to the concurrency level. By default, it is divided into 16 segments.
4. ConcurrentHashMap allows multiple threads can perform read operation without locking the ConcurrentHashMap object.
5. It works based on segment locking or bucket locking. In ConcurrentHashMap multiple threads can perform retrieval operation but updating operation can be performed only by one thread. For updating operations, a particular segment must be locked.
6. It doesn’t allow null as key or value.
How to create ConcurrentHashMap?
To create a ConcurrentHashMap, we can use the constructors of ConcurrentHashMap class. There are a number of constructors that are used to create a ConcurrentHashMap. Let’s discuss all the constructors of the ConcurrentHashMap class.
constructors of ConcurrentHashMap class
1. ConcurrentHashMap() : It is the default constructor of ConcurrentHashMap class that creates an object of ConcurrentHashMap with default capacity 16. It has a default load factor 0.75 and a concurrency level is 16.
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapExample
{
public static void main(String args[])
{
ConcurrentHashMap<Integer, String> concurrentHashMap = new ConcurrentHashMap<Integer, String>();
concurrentHashMap.put(1, "JavaGoal.com");
concurrentHashMap.put(2, "Learning");
concurrentHashMap.put(3, "Website");
System.out.println("Object from ConcurrentHashMap: "+ concurrentHashMap);
}
}
Output: Object from ConcurrentHashMap: {1=JavaGoal.com, 2=Learning, 3=Website}
2. ConcurrentHashMap(int initialCapacity) : It is also used to create an empty ConcurrentHashMap with specified capacity. It has a default load factor and concurrency level is 16.
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapExample
{
public static void main(String args[])
{
ConcurrentHashMap<Integer, String> concurrentHashMap = new ConcurrentHashMap<Integer, String>(10);
concurrentHashMap.put(1, "JavaGoal.com");
concurrentHashMap.put(2, "Learning");
concurrentHashMap.put(3, "Website");
System.out.println("Object from ConcurrentHashMap: "+ concurrentHashMap);
}
}
Output: Object from ConcurrentHashMap: {1=JavaGoal.com, 2=Learning, 3=Website}
3. ConcurrentHashMap(int initialCapacity, float loadFactor): This constructor creates a ConcurrentHashMap with specified capacity and specified load factor. But it has default concurrency level is 16.
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapExample
{
public static void main(String args[])
{
ConcurrentHashMap<Integer, String> concurrentHashMap = new ConcurrentHashMap<Integer, String>(10, 0.80f);
concurrentHashMap.put(1, "JavaGoal.com");
concurrentHashMap.put(2, "Learning");
concurrentHashMap.put(3, "Website");
System.out.println("Object from ConcurrentHashMap: "+ concurrentHashMap);
}
}
Output: Object from ConcurrentHashMap: {1=JavaGoal.com, 2=Learning, 3=Website}
4. ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel): This constructor is used to create an object of ConcurrentHashMap with specified capacity, load Factor, and concurrency level.
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapExample
{
public static void main(String args[])
{
ConcurrentHashMap<Integer, String> concurrentHashMap = new ConcurrentHashMap<Integer, String>(10, 0.80f, 8);
concurrentHashMap.put(1, "JavaGoal.com");
concurrentHashMap.put(2, "Learning");
concurrentHashMap.put(3, "Website");
System.out.println("Object from ConcurrentHashMap: "+ concurrentHashMap);
}
}
Output: Object from ConcurrentHashMap: {1=JavaGoal.com, 2=Learning, 3=Website}
5. ConcurrentHashMap(Map m): This method creates an object of ConcurrentHashMap with specified map. It copy all the objects from specified map to ConcurrentHashMap object.
import java.util.HashMap;
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapExample
{
public static void main(String args[])
{
HashMap<Integer, String> hashMap = new HashMap<Integer, String>();
hashMap.put(1, "JavaGoal.com");
hashMap.put(2, "Learning");
hashMap.put(3, "Website");
ConcurrentHashMap<Integer, String> concurrentHashMap = new ConcurrentHashMap<Integer, String>(hashMap);
System.out.println("Object from ConcurrentHashMap: "+ concurrentHashMap);
}
}
Output: Object from ConcurrentHashMap: {1=JavaGoal.com, 2=Learning, 3=Website}
ConcurrentHashMap internal working
Before moving further, we recommend you please read then internal working HashMap. You can read it here.
Like HashMap and HashTable, the ConcurrentHashMap is also used to HashTable data structure. But it is using the segment locking strategy to handle the multiple threads. A segment is a portion of ConcurrentHashMap and ConcurrentHashMap uses a separate lock for each thread. Unlike Hashtable or synchronized HashMap, it doesn’t synchronize the whole HashMap or HashTable for one thread.
As we have seen in the internal implementation of the HashMap, the default size of HashMap is 16 and it means there are 16 buckets. The ConcurrentHashMap uses the same concept is used in ConcurrentHashMap. It uses the 16 sperate locks for 16 buckets by default because the default concurrency level is 16. It means a ConcurrentHashMap can be used by 16 threads at same time. If one thread is reading from one bucket(Segment), then the second bucket doesn’t affect it.

How does ConcurrentHashMap implementation increase performance?
As we have read in the above section, the ConcurrentHashMap performs segment locking in a multithreading environment. It allows performing read operations concurrently without any blocking. It can perform retrieval operations and may overlap with update operations. We can perform read operations by multiple threads at the same, but the only thread can perform updation operation at a time. The read operations return the result updated by the most recently updated operations that mean the read operation may not fetch the current/in-progress value. Memory visibility for the read operations is ensured by volatile reads.
Why we need ConcurrentHashMap in java?
As we know HashTable and HashMap works based on key-value pairs. But why we are introducing another Map? As we know HashMap is not threaded safe, but we can make it thread-safe by using Collections.synchronizedMap() method and HashTable is thread-safe by default. But a synchronized HashMap or HashTable is accessible only by one thread at a time because the object get the lock for the whole HashMap or HashTable. Even multiple threads can’t perform read operations at the same time. It the main disadvantage of Synchronized HashMap or HashTable, which creates performance issues. So ConcurrentHashMap provides better performance than Synchronized HashMap or HashTable.
Java ConcurrentHashMap example
We have seen a lot of things about ConcurrentHashMap. Let’s see an example of ConcurrentHashMap in Java. Like a HashMap, here we will use the key-value pair and then getting the collection view.
import java.util.Iterator;
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapExample
{
public static void main(String args[])
{
ConcurrentHashMap<String, String> hashMap = new ConcurrentHashMap<String, String>();
hashMap.put("CHD", "123ABC");
hashMap.put("Mohali", "CBA321");
hashMap.put("KKR", "55RR");
for(String key : hashMap.keySet())
{
System.out.println("Key from Map: "+key);
System.out.println("Value from Map: "+ hashMap.get(key));
}
}
}
Output: Key from Map: KKR
Value from Map: 55RR
Key from Map: Mohali
Value from Map: CBA321
Key from Map: CHD
Value from Map: 123ABC
Fail-safe iterator in ConcurrentHashMap
As we know we can’t modify the Collection during transversal. If we try to modify them during the iteration, it throws ConcurrentModificationException. But the Concurrent collection overcome from this problem. If we talk about ConcurrentHashMap, it doesn’t throw an exception if we modify it while iterating because the iterator returned by the ConcurrentHashMap is fail-safe.
import java.util.Iterator;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapExample
{
public static void main(String args[])
{
// Creating ConcurrentHashMap
Map<String, String> cityTemperatureMap = new ConcurrentHashMap<String, String>();
cityTemperatureMap.put("Delhi", "24");
cityTemperatureMap.put("Mumbai", "32");
cityTemperatureMap.put("Chennai", "35");
cityTemperatureMap.put("Bangalore", "22" );
Iterator<String> iterator = cityTemperatureMap.keySet().iterator();
while (iterator.hasNext())
{
System.out.println(cityTemperatureMap.get(iterator.next()));
// adding new value, it won't throw error
cityTemperatureMap.put("Kolkata", "34");
}
}
}
Output: 24
35
34
32
22