We have learned HashMap in java in recent posts. As we know HashMap works based on
key-value pair that is known as the entry. But how does HashMap internal implementation works? It is one of the most common questions from HashMap interview questions. In this post, we will see the internal working of HashMap in java or HashMap internal implementation in java.
Here is the table content of the article will we will cover this topic.
1. HashMap internal implementation or Internal working of HashMap?
2. What is hashing in java?
3. How does put method work?
4. How collisions are resolved?
5. How does get method work?
Before moving further, we should know about the equals() method and hashCode() method. HashMap stores the data in Key-Value pair and it uses node to store the key-value. It uses the Node class that is a static inner class to represent the pair(Key-Value) as a node. The HashMap contains an array and LinkedList data structure internally for storing Key and Value. Let’s see the object of the structure of HashMap or Internal working of HashMap in JDK:
final int hash;
final K key;
V value;
Node<K,V> next;
In HashMap, each node has some specific data that is hashCode, key, value, and address of the next node.
HashMap internal implementation or Internal working of HashMap
The internal implementation of HashMap depends upon the hash code of the object. It performs each operation based on hashCode() method and equals() method. If you are not familiar with the hashcode() method and equals() method, then please read it from here.
The HashMap uses the Hashing technique to store and retrieve the data. Hashing is a technique that is used to get the unique integer value.
What is hashing in java?
Hashing is a technique that converts an object into a unique integer value. This unique integer number is known as the hashcode. The hashing technique uses the hash function, which invokes the hashcode() method to generate a number.
Whenever we put any object in HashMap, the put(key, value) method calculates the hashCode of the key and inserts the value in HashTable. But this is not a blind process, it takes a few steps to put the object in HashTable. To understand the process, we need to understand how does put(key, value) method work?
How does put method work?
1. First of all, it checks the key object is null or not? If the given key is null, then it will directly go for position 1 i.e table[0]. Because the hashcode for null is always 0.
2. If the key is not null then the hashCode() method is used to get the hash value. The hash value is used to calculate the index value in the table to store the key-value pair.
3. There might be a chance, the hashCode() method can return a very high or low hash code value. It totally depends on the implementation of the hashCode() method in the class. To solve this issue, the hash() function to bring hash value in the range of array index size.
4. After calculating the hash code, it calls the indexFor(hash, table.length) method to calculate the particular index to store the pair. It accepts the hash code of the key and length of the table[] array. And returns the index value.
5. Each pair stores as a node on a specific index in the table and that called a bucket. A bucket is used to stores the nodes. A bucket can contain two or more nodes and the LinkedList structure is used to connect the nodes. We will discuss it later in the Hash collision.

Now you have understood how a HashMap stores all the values in HashTable based on a unique key. It replaces the value if the given key already exists in HashMap.
Let’s take an example and see how it works in memory. As you can see, there can be any number of buckets in HashMap. Each bucket maintains the LinkedList structure of nodes.

How collisions are resolved?
We have seen how HashMap stores each pair by use of hashcode. But there may be a chance that two unequal objects can have the same hash code value? Suppose two objects have the same hashcode then how it stores the object in HashTable? Let’s find the answer
If there are two different objects having the same hashcode then they will be stored in the same bucket. The bucket uses the LinkedList structure to store more than two nodes. Here HashMap performs a few steps.
1. HashMap checks, whether there is an entry already exist with the same in hashcode in a bucket or not?
2. If there is no entry already present, then node is stored at the index value of table.
3. But if entry is already existing then it checks the reference of the node. If the node is not referencing any next node then-current entry object becomes the next node in LinkedList. But If it is referencing, then the procedure is followed until next is evaluated as null.
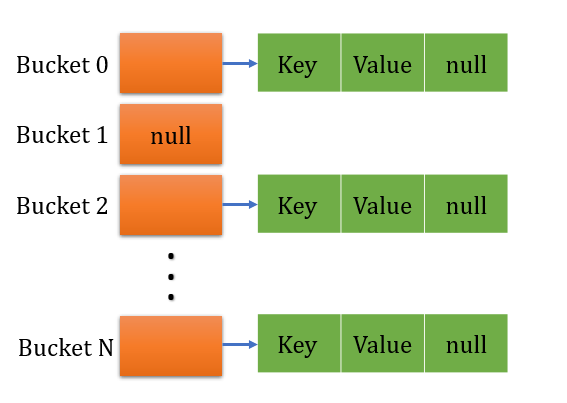
How does get method work?
We have seen HashMap stores the data in buckets and there can be any number of buckets. Each bucket stores multiple nodes in the LinkedList structure. But one question comes in mind, how does get(key) method work based on key. The get(key) method performs some steps.
Step 1: Like put() method, it also checks whether the given key is null or not. If the given key is null, it calls the getForNullKey() method.
Step 2 : If the given key is not null, then it internally calculates the hash code of the specified key is calculated.
Step 3 : Get the index value by use of indexFor() method. It uses the hashcode value.
Step 4 : By use of index value it gets the node from bucket that contains key value pair. If bucket has multiple nodes in LinkedList structure, it will iterate though linked list at that position and checks for the key using equals() method.